NVIDIA Announces Unified Memory In CUDA 6
Gabriel Roşu / 10 years ago
![]()
NVIDIA has announced unified memory support in CUDA 6. The hope is that this will greatly ease the process writing programs that use CUDA, by simplifying the process of managing memory access.
Former implementations of CUDA relied on the programmer to manage the exchange of information from CPU/system memory to GPU memory. This creates a sizeable and somewhat unnecessary overhead for coders. With the new unified memory system, though, programmers can access and operate on any memory resource, regardless of which pool of memory the address actually resides in.
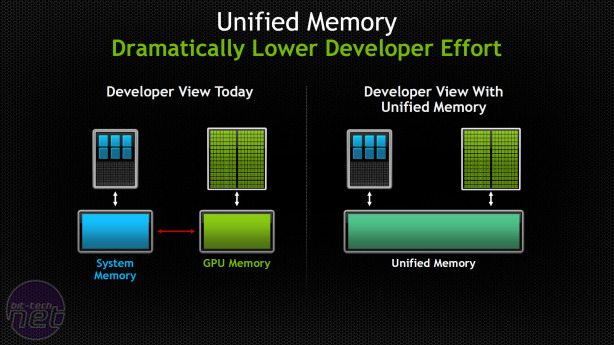
The system doesn’t actually eliminate the physical requirement to copy the memory contents from one pool to another but does remove the need for programmers to manage that part of the process – CUDA 6 does it automatically.
This is contrast to the unified memory implementation that AMD has been lauding on its upcoming Kaveri APUs. Those chips actually use the same block of memory, eliminating the need to copy the data from one block to another entirely.
There is a possibility that the new CUDA 6 solution will have a negative impact on performance, as finer control of memory management is taken away from the program. However, coders will still have the option to manually control memory if needed, while providing a simpler solution for those that don’t require more granular control.

NVIDIA has also announced that CUDA 6 will include new BLAS and FFT libraries that a tuned for multi-GPU scaling, with them optimised to support up to 8 GPUs in a node. Another key aspect that NVIDIA states regards the open source parallel programming standard OpenACC, which will be incorporated into the GNU Compiler Collection bringing GPU acceleration support to the popular compiler.
Thank you Bit-Tech for providing us with this information
Images courtesy of Bit-Tech


















