AMD Details Vega Next-Gen GPU Architecture
Samuel Wan / 7 years ago

After releasing their Vega architecture teaser earlier in the week, AMD has finally shared some details for their next-generation GPU Architecture. Unlike Polaris which was merely a sizeable update for GCN, Vega appears to be taking GCN to an entirely new level with new hardware unit never before seen. Frist, let’s start with the headline feature for Vega, the VRAM and memory management.
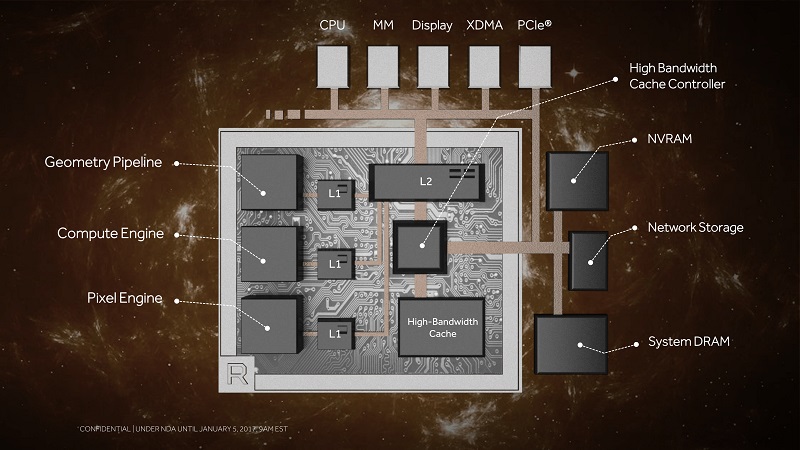
As we’ve known for quite a while, Vega uses HBM2 which replaces the original HBM (High Bandwidth Memory) with double the bandwidth and up to 8x the capacity per stack. This means AMD can now put up to 32Gb using the same 4 stacks we saw with Fiji. Instead of calling it VRAM, AMD is termed the HBM2 as High Bandwidth Cache. No reason is really given for this change but I guess it’s to distinguish the faster HBM2 from the usually slower GDDR5(X) VRAM.
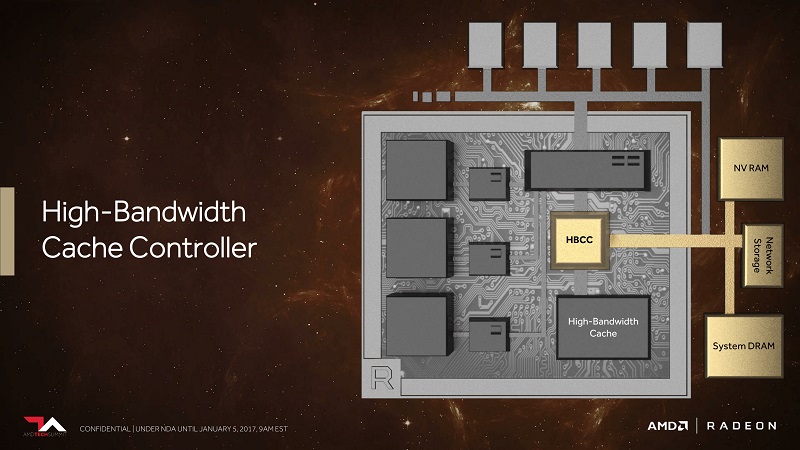
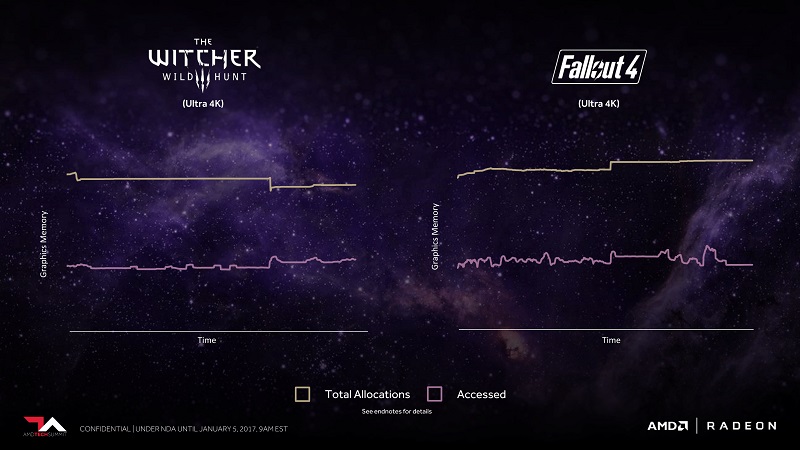
To make the most out of it, AMD is also introducing a new High Bandwidth Cache Controller to control both on-die and off-die memory. Today’s games tend to allocate as much memory as possible but rarely use all of it. With the HBCC, AMD is planning to optimize the memory allocation to achieve better efficiency. We saw something similar with Fiji where AMD was able to get a lot further with 4GB than any other cards.
Moving on into the Vega Next-Gen Compute Unit (NCU), we get an idea of just how much has changed. The new CUs are now capable of running double 16bit and quadruple 8bit operations relative to 32bit ops. While more useful for professional programs, it does bring feature parity with Nvidia. Fundamentally, the overall structure remains the same as with GCN but it is now optimized for higher clock speeds and IPC. AMD’s GCN cards have been limited in overclocks due to their design and this should help AMD close the gap.

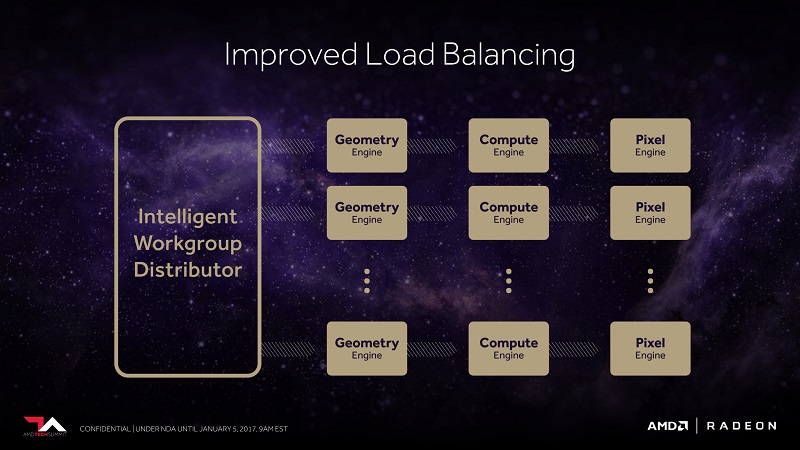
AMD is also aiming to get more efficiency out of their existing resources. Instead of being limited to the 4 shader engines of GCN 1.1+, Vega is able to distribute work better to the engines to optimize and balance the workload. To keep up with the other improvements, the geometry engine is also getting a revamp with up to 2x improvement in peak throughput. There is no word on this was achieved. One hint may be in what AMD is calling primitive shaders which discard hidden/unnecessary primitives to save on resources.
This trend in continued with the rasterizers and ROPs. Vega adds support for Draw Stream Binning Rasterizer which allows tile based binning. This means Vega can more efficiently break the workload into smaller chunks and reduce memory access. It also allows hidden pixels to be culled better and reduce the unnecessary workload on the rest of the pipeline. For the ROPs, AMD has added the ability to directly access the L2 cache to speed up work.

Overall, AMD is painting a very strong picture for the Vega Next-Gen GPU Architecture. While GCN has proven its worth and forethought with its longevity, the time to move on has become apparent. As we saw with Polaris, merely updating the components of GCN isn’t quite enough and new additions are required. While the GCN name may continue with Vega, it may soon become an entirely different beast unrecognizable from the Tahiti of 2011.


















